この記事は WordPress Advent Calendar 2014 の 10日めの記事として書いています。
WordPress に限らず Advent Calendar への参加は初めてです。
11月の終わりになってそう言えばそんな時期だなと思い、今年はどんなカレンダーがあるのだろうと Web サーフィン (死語) をしていたところ、WordPress Advent Calendar が埋まっていないのを見つけました。
そして、枠を埋めるつもりで気軽に応募し、この記事を書いています。
ちなみに私自身は WordPress プラグインの作者 (プラグインその1、その2) ですが、本業は WordPress に関係ありません。
Advent Calendar 用として何を書くかについてはいろいろ悩みました。
利用者向けに書いてみたい気もしましたが、説教臭くなってしまう恐れがあるので(「何故、自前の WordPress なんでしょうか?ブログサービスじゃダメなんでしょうか?」とかw)、結局開発に興味ある方向けに、解説されることの少ない投稿の更新処理についてコードを追いかけてみることにしました。
というわけで今回は投稿編集画面で「公開」/「更新」ボタンを押したときの処理を見ていきます。
是非実際にコードを参照しながらお読みください。
なお、コードは WordPress 4.01 のものを参照しています。
紛らわしいのですが、HTTP メソッドの POST は大文字で、WordPress の投稿を指す際は小文字の post で表すことにします。
フォームの submit
まず、投稿編集画面ですが、wp-admin/post-new.php (新規) あるいは wp-admin/post.php (更新) によって表示されます。
編集画面を表示する実体としてはどちらも wp-admin/edit-form-advanced.php によって処理されるのですが、ここには深入りしません。
post-new.php の処理で注目したいのが、71行目で get_default_post_to_edit() を呼んでいる点です。
この時点でデータベース内に投稿データが作成され、新しい post ID が付与されることになります。
つまり、新規投稿であろうが更新であろうが、公開/更新ボタンを押したときの処理はデータベース内の post データを更新する処理になり、実のところ submit されたフォームデータの処理から先は共通になっています。
編集画面は post.php に POST するフォーム (form 要素は id=post) になっています。
hidden 項目の一つとして (name=’action’, value=’editpost’) という項目が POST されます。
これが wp-admin/post.php 17行目の wp_reset_vars() で $action = ‘editpost’ となり、104行目からの switch ($action) で edit_post() が実行されます。
以下関数名を使って追いかけていきます。
edit_post() では、引数が null で実行されることになるので POST されたデータが $post_data に設定されます。
$post_ID も POST された値が用いられます。
そしてもろもろの前処理 (詳細省略) を行った後 320行目で wp_update_post() を呼びます。
引数の $postarr には編集画面のフォームより POST された投稿データが含まれています。
3541行目の get_post() で $post にデータベース内の投稿データがセットされます。
attachment の更新の場合は wp_insert_attachment() をコールしたりとかありますが、今回は post なので wp_insert_post() が呼ばれます。
まあ、大した処理をしていないのでさっさと次に行きましょう。
次の wp_insert_post() の処理が最も重要です。
引数 $postarr には編集画面のフォームより入力された投稿データが含まれています。
wp_update_post() に続きここでも get_post() でデータベースの投稿データを引っ張りだしています (3095行目)。
非効率な気もしますが、get_post() から呼ばれる get_instance() で読んだデータをキャッシュする仕組みがあるようなので大丈夫でしょう。
3090行目からの if 文の処理ですが、編集画面フォームから submit したときの処理は新規の場合でも $postarr[‘ID’] が存在して $update = true になります。
では $update = false となるのはどんな時かと言うと、編集画面を表示する際に get_default_post_to_edit() 経由で呼ばれたときですね。
そして、この wp_insert_post() はかなり長いのですが、やっていることの大半は post データの設定です。
どこでデータベースが更新されるかわかりづらいのですが、$update = true の場合は 3341行目の $wpdb->update() で更新されます。
この周辺にはアクションフック/フィルターフックも多数存在するので、この wp_update_post() だけでも一度真剣に読んでみると良いと思います。
さて、ここまでで投稿されたデータは無事データベースに反映されましたが、リビジョンの処理についてもう少し見てみます。
wp-includes/default-filters.php 内で既定のフック関数が登録されているのですが、この中に post_updated のフック関数として wp_save_post_revision() が登録されています (251行目)。
これが wp_insert_post() から呼び出されます (3478行目)。
それではリビジョン関連処理を見ていきます。
下の図は投稿更新時のリビジョン関連処理の概要を表したものです。
同じ色は同じコンテンツを表していますが、このように現在の post の内容と同一のものが最新リビジョンとして post_type=’revision’ でデータベース内に存在します。
詳しくはこちらの記事をどうぞ。
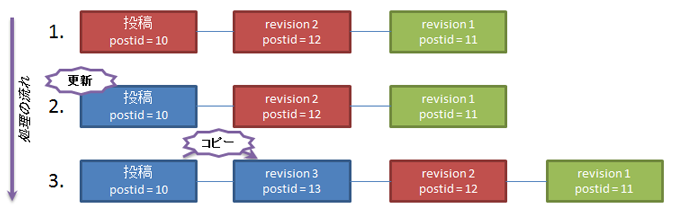
では wp_save_post_revision() の処理を見ていきます。
まず wp_get_post_revisions() で更新された投稿についての全リビジョンを取得します (104行目)。
そして、最新のリビジョン、すなわち更新前の post と同じデータを持つリビジョンの ID を $last_revision にセットします (106行目からの foreach ループ)。
続く、127行目の if 文では内容に変更があったかを確認し、変更が無いようであればそのまま return してしまいます。
その後に _wp_put_post_revision() を呼んで新しい post と同じ内容を持つ post_type=’revision’ のデータをデータベース内に作成します (142行目)。
この処理において _wp_put_post_revision() から wp_insert_post() が呼ばれるわけです。
「$postarr のデータが post_type=’post’ でなく、post_type=’revision’ だったら処理はどう変わるのだろう?」という新たな視点から wp_insert_post() を読み直すことができるわけですねw
wp_put_post_revision() を呼んだ後 (144行目以降) は不要となったリビジョンの削除処理です。
保持するリビジョン数は wp_revisions_to_keep() が返す値を使っていますが、この関数の中をみると、WP_POST_REVISIONS を設定する他にも wp_revisions_to_keep フックをつくれば何世代リビジョンを保持するかを指定できることがわかります。
まとめ
ここまで説明してきた関数をコールツリーにまとめておきます。

いかがでしょう?
思ったより簡単に読めたのではないでしょうか?
この記事がきっかけで Core のコードに興味を持ち、実際にプラグインを書いたりする人が増えるととても嬉しいです。
他にも WordPress 関連記事はありますので、気が向いたらどうぞ。
なお、投稿更新「編」としましたが、関連記事がこれっきりになる可能性がそれなりに高いことをあらかじめご承知おきくださいw
明日は岡本秀高さん、濱田文さんです。
何と 2つの記事が読めちゃいます!